Neben der großen Zahl an online verfügbarer Korpora stehen im CIP-Labor des Fachbereichs 10 einige lokale Korpora zur Verfügung. Diese Korpora können mit Konkordanz-Software wie AntConc oder WordSmithTools genutzt werden.
Korpora der sog. „Brown family of corpora“
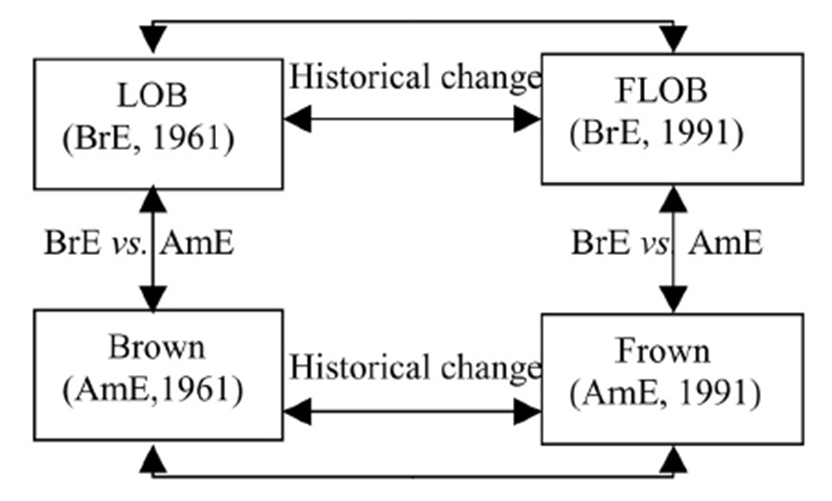
- The Brown University Corpus (Brown).The 1st modern corpus of English; edited AmE, text samples from 15 categories (genres).Time span: 1961. Written corpus. 1million words, 500 text samples (2000 words each)
- The Lancaster Oslo/Bergen Corpus (LOB). British match for the BROWN, edited BrE, text samples from 15 categories (see BROWN). Time span 1961. Written corpus. 1 million words.
- The Freiburg Brown Corpus. American English, text samples from 15 categories (genres). Time span: 1992. Written corpus. 1 million words.
- The Freiburg-Lancaster-Oslo/Bergen Corpus (FLOB).British match for the FROWN, edited British English, text samples from 15 categories (genres). Times Span: 1991. Written corpus. 1 million words.
- The Australian Corpus of English (ACE). Australian match for the BROWN (mind: a different time span), text samples from 15 categories (see BROWN). Time span: 1986. Written corpus. 1million words, 500 text samples (2000 words each).
- The Wellington Corpus of Spoken New Zealand English (WSC). Formal, semi-formal and informal speech, monologue and dialogue, broadcast and private. Time span: 1988-1994. (90% 1990-1994). Spoken corpus. 1 million words, 2000 words extracts.
- The Wellingten Corpus of Written New Zealand English (WWC). New Zealand match for the LOB (mind: a different time span), text samples from 10 categories (see the LOB). Time span: 1986-1990. Written corpus. 1 million words, 500 text samples.
Weitere Korpora zu Varietäten des Englischen
- The Corpus of Spoken American English (the Santa Barbara Corpus) (CSAE). Spontaneous speech, American English, different text types (e.g.dialogue, story-telling, food preparation); speech files. Time span: 1991. Spoken corpus. 249.000 words.
- The International Corpus of English (ICE). World Englishes, different genres (e.g. broadcast news, press news reports, novels, short stories). Time span: 1990s till present. 60% spoken, 40% written. 1 million words (500 samples, 2000 words each) for each variety covered. Annotation: POS tagging, syntactic parsing. Components: Great Britain (ICE GB), East Africa (ICE EA), Hong Kong (ICE HK), India (ICE IND), Philippines (ICE PHI), Jamaica (ICE JA), New Zealand (ICE NZ).
Diachrone Korpora
- A Representative Corpus of Historical English Registers, Version 3.1. (ARCHER). British English and American English, various genres (e.g. fictional conversation, letters, news). Time span: 1950-1990. Written Corpus. 1,7 million words.
Lernerkorpora
- The Louvain Corpus of Native English Essays (LOCNESS). Native English essays, British and American students. Comparable to the ICLE. Written Corpus. 324.000 million words.
- The International Corpus of Learner English (Versions 1 and 2). (ICLE, ICLEv2). Essays written by ‘advanced’ students of English, various L1 backgrounds (e.g. Bulgarian, Chinese). Comparable to the LOCNESS. Version 2 contains more data and a built-in concordancer. Time span: Project start 1990. Release 2002 and 2009. Written corpus.
Version 1: 2.5 million words.Version 2: 3.7 million words. Annotation: POS, lemmas, gender, age, type of task. -
The Louvain Corpus of English Native Conversation (LOCNEC). Oral data (interviews) produced by English native speakers (students). Comparable to LINDSEI. Spoken corpus. 162,000 words.
- The Louvain International Database of Spoken English Interlanguage (LINDSEI). Oral data (interviews) produced by advanced students of English, various L1 backgrounds. Time Span: Project start 1995, corpus release 2010.
