Bajo el seminario de “Lingüística del contacto de lenguas – el code copying entre el individuo y el colectivo”, como ya se ha indicado en la introducción del blog, hemos conocido distintas perspectivas acerca de este fenómeno, así como la posibilidad de relación entre los distintos modelos a la hora de poder analizar un discurso donde se dé una o más alternancias de código.
Para entender con claridad por qué hemos elegido los modelos de Johanson y Matras que vamos a presentar de forma detallada más adelante en el análisis de nuestro corpus, es importante conocer muy brevemente los otros modelos consultados en clase y su principal enfoque.
A lo largo del seminario, la Dra. Salzmann nos ha proporcionado acceso a los siguientes textos y/o capítulos, que nos han permitido conocer una gran variedad de modelos provenientes de distintas áreas lingüísticas y con diferentes enfoques. Todas las semanas debíamos resumir (y dado que estaban en inglés, también traducir) uno de los textos o artículos, lo que nos ha posibilitado entender éstos de una manera mucho más profunda. La Dra. Salzmann especificó además, que escribiéramos las preguntas que nos surgían en los resúmenes para luego poder resolver las dudas en la clase virtual, lo que también nos ayudó mucho a la hora dar forma a este proyecto.
La tabla siguiente muestra muy breve los textos y modelos consultados y discutidos en el seminario, de los cuales vamos a centrarnos solamente en los que consideramos fundamentales en cuanto a justificar la elección de los dos modelos relevantes para nuestro análisis de corpus y, por lo tanto, parte central del presente blog.
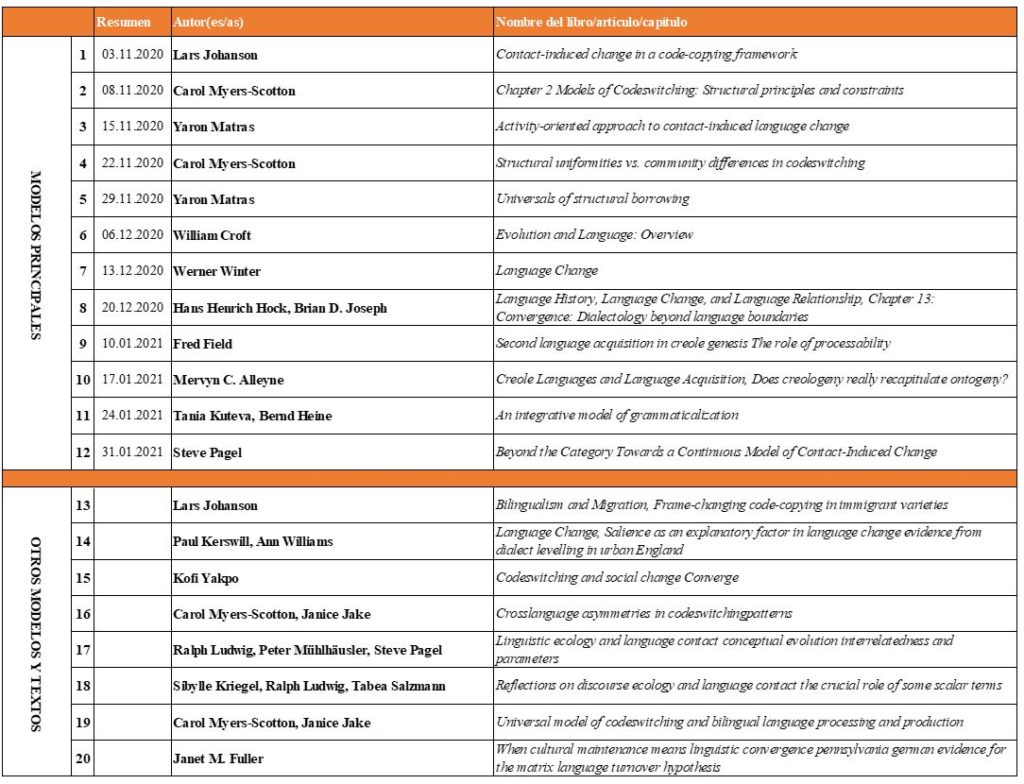
Foto: Marina Cots Terreu y Kira Molina
En primer lugar, pudimos conocer los debates actuales sobre la diferencia entre code-mixing, code-switching y borrowing y pudimos encontrar respuestas a algunas de las preguntas subyacentes que realiza Myers-Scotton en su artículo como:
¿Cómo funciona la lengua en la mente?
¿Existen dos lenguas separadamente o se mezclan para crear una nueva?
En el primer caso, ¿cuál predomina? ¿Cómo funciona esa dominancia?
En el segundo caso, ¿existe un nuevo código? Si es así, ¿cómo funciona?
¿Por qué se debe distinguir entre “deep language” y “lengua superficial”?
En este contexto, dedicamos especial atención al Matrix Language Frame Model (MLF) de Myers-Scotton, que personalmente percibimos como muy complejo y consideramos que acceder al modelo de Myers-Scottons requería amplios conocimientos previos y un compromiso con la materia en particular. Se trata de un modelo general de producción lingüística de cuatro niveles: el nivel conceptual, el léxico mental, el formulador y el nivel de superficie [o en inglés: the conceptual level, the mental lexicon, the formulator, and the surface level].
También nos parece interesante el modelo de code copying de Johanson, que además nos resulta muy útil para nuestro análisis más adelante:
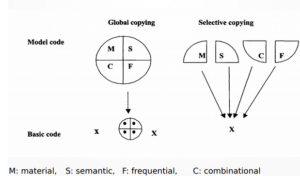
Foto: Material de lectura, Dr. T. Salzmann (Powerpoint)
Johanson separa un código modelo [Model code] que es el código a partir del cual se realizan las copias y un código básico [Basic code] que viene a ser el código en el que se insertan las copias. Lo importante, según Johanson, es que todas las copias están sujetas a una forma de adaptación (incluso las copias globales). Esta adaptación, que a menudo va unida a la creatividad del hablante, la describe como una cierta modificación en el sentido del sistema del código básico. Es importante comentar que Johanson está convencido de que para los hablantes no hay fusión de sistemas lingüísticos de por medio, sino que estos sistemas existen siempre por separado. Desde una perspectiva histórica colectiva, mantiene que los sistemas separados son dinámicos y por lo tanto cambiantes.
Además de esto, Johanson considera la adopción, imposición y el desplazamiento. En este contexto describe la adopción y la imposición como fenómenos de convergencia. Con la adopción los hablantes del código no dominante A insertan copias del código dominante B.
En la imposición los hablantes del código no dominante A insertan material de A en su versión del código dominante B.
Y en el desplazamiento – como ya nos dice el nombre – B elimina a A.
Una conclusión muy importante de Johanson en el contexto del seminario es que se dedica con su modelo también al tema de la habitualización y la convencionalización. Así, Johanson mantiene que lo que comienza como un caso momentáneo de copia, resultado de un acto individual singular, puede acabar contribuyendo a una nueva norma lingüística. Esto significa que las copias más (o menos) habituales se producen con frecuencia, regularidad o normalidad en individuos o también grupos, lo cual puede generar nuevos elementos lingüísticos que inicialmente fueron considerados ‘ajenos’ al código básico. Para Johanson, la convencionalización significa una integración con respecto a la aceptación en el habla de comunidades.
En el modelo de Matras, que también juega un papel importante en nuestro análisis, se destacan las siguientes preguntas subyacentes:
¿Cómo funciona la adquisición de lenguaje (en bilingües)?
¿Cómo existe y es procesado el lenguaje en nuestra mente?
¿Cómo funciona la interacción multilingüe?
¿Qué pasa en el habla multilingüe?
Foto: Material de lectura, Dr. T. Salzmann (Powerpoint)
Con esto, Matras parte de otro punto que Johanson, por ejemplo, y se dedica especialmente a la función y adquisición del lenguaje en bilingües. Otro punto que diferencia Matras de Johanson es la manera de analizar cómo es procesado el lenguaje en nuestra mente. Especialmente enfoca también el habla multilingüe y los procesos relevantes y su interacción.
En este contexto, Matras elabora “el continuo de la creatividad e innovación inducida por el contacto” llamado en inglés “The continuum of contact-induced creativity and innovation” ilustrado a continuación:

Foto: Material de lectura, Dr. T. Salzmann (Powerpoint)
Una vez descritos los modelos que nos deparan especial atención y que son enfoque de nuestro análisis, queremos comentar además el Code Hybridization Continuum (CHC) de Kriegel, Ludwig und Salzmann, que tuvimos la oportunidad de conocer en el seminario. Estos últimos, también desarrollaron un Conventionalized Systemic Integration Continuum (CSIC), así como el Structural Systemic Integration Continuum (SSIC), que no discutiremos en detalle, ya que no es parte de nuestra investigación, pero que igualmente queríamos mencionar, dado que parte del enfoque ecolingüístico de nuestro seminario fue el modelo sobre tres niveles de la ecología lingüística de Ludwig, Mühlhäusler y Pagel, como modelo multidimensional de contacto lingüístico.
En cuanto a la cuestión fundamental de los fenómenos del individuo y del colectivo y su nexo, así como de la transición de uno al otro, nos gustaría tratar sólo brevemente los modelos, ya que tales consideraciones vendrán a colación, sobre todo en la parte final de nuestro blog (conclusión) y tras la reflexión sobre nuestro propio análisis, para así poder completar el blog de forma holística y teniendo en cuenta todos los aspectos importantes.
Otro modelo importante que conocimos durante la clase es la “Theory of utterance selection” de Croft, en la que habla del cambio lingüístico basándose en la teoría de la evolución biológica y que, a pesar de ser un enfoque interesante, tampoco vamos a centrarnos, ya que no es relevante para el análisis que vamos a realizar en este proyecto en concreto.
A pesar de haber podido solamente describir por encima lo que en clase hemos trabajado con más detalle, nos ha parecido importante el poder dar, por lo menos, una visión general de algunos modelos. Como hemos mencionado anteriormente, para este proyecto hemos decidido utilizar los modelos de Matras y Johanson, pero para llegar a esta decisión ha sido de vital importancia el poder comparar los distintos modelos vistos y así ver cuál (o en este caso, cuáles) se adaptan mejor a nuestro corpus.
Autoras: Kira Molina y Marina Cots Terreu