
Foto: Canva
A lo largo del seminario “Lingüística del contacto de lenguas – el code copying entre el individuo y el colectivo”, hemos visto paulatinamente distintas maneras de analizar el code-copying a través de los modelos que la Dr. Tabea Salzmann nos ha proporcionado. Para ello, cada semana debíamos leer y resumir un texto en donde se exponía uno de estos modelos. Dado que desde el inicio del seminario pudimos trabajar en grupo, aprendimos a trabajar conjuntamente desde el principio.
A grandes rasgos, trabajamos de la siguiente manera:
- Creamos una carpeta compartida en Google Drive, donde las dos tenemos acceso a la creación de documentos y a la modificación de estos.
- Hablamos/escribimos vía WhatsApp las ideas que se nos ocurren para el trabajo. Esta parte incluye: Formulación de preguntas, posibles cambios en el enfoque del proyecto o de los modelos utilizados, información acerca de la actualización de documentos en la carpeta compartida, etc.
- Cada vez que decidimos realizar un cambio y/o actualizamos algún documento, la persona que se encarga de llevarlo a cabo informa a la otra y, una vez terminado, ésta relee el texto y comenta los cambios o realiza sugerencias. Este intercambio de ideas suele conllevar una fructífera discusión a través de varios canales. Finalmente, la persona que ha realizado el cambio lee nuevamente los comentarios/sugerencias y se llega a un consenso entre las dos partes.
Foto: Marina Cots Terreu y Kira Molina
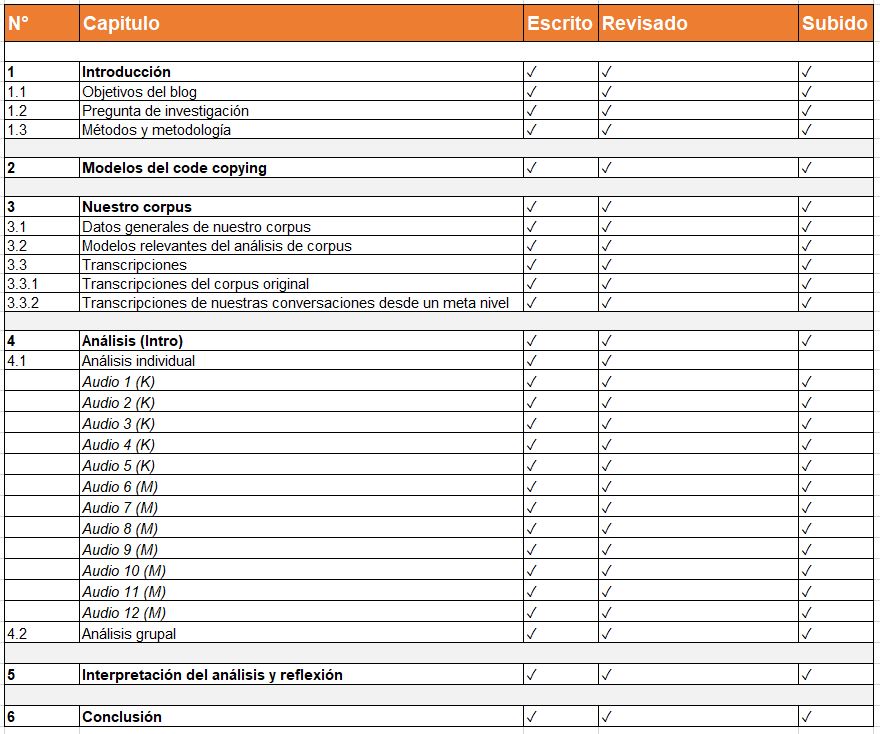
Foto: Marina Cots Terreu y Kira Molina
Desde el inicio de este proyecto, hemos ido trabajando en la estructura general, pues a pesar de tratarse de un blog, queríamos mantener la claridad que puede ofrecer un trabajo escrito de forma convencional. Mientras estábamos corrigiendo el apartado de metodología, nos dimos cuenta que trabajando en este formato, no quedaba claro cómo se habían trabajado las partes conjuntas (que constituyen la mayor parte del proyecto). Por este motivo, hemos decidido explicar cómo hemos trabajado, intentando así mantener un mayor grado de transparencia.
Puesto que nuestra intención es analizar trozos de conversaciones, vamos a utilizar datos observacionales como método de análisis. Por ejemplo, buscar las palabras de la lengua insertada: ¿Se trata de palabras sueltas? ¿De sintagmas? ¿De frases enteras? ¿De temas similares (en este caso, también sinónimos)? ¿Por qué surge esto?
Si bien nuestra idea originalmente era analizar partes de conversaciones espontáneas entre hablantes mayormente uruguayos en un contexto alemán, al hablar entre nosotras acerca del proyecto nos dimos cuenta de que nosotras mismas estábamos alternando constantemente. Lo interesante en esta segunda situación fue, no sólo que nuestras conversaciones a menudo se daban a nivel metalingüístico, sino que hablamos distintas variedades de español (lengua matriz en la mayoría de nuestras conversaciones) y con el paso de los meses y de forma totalmente involuntaria, hemos desarrollado un principio de koiné. Teniendo en cuenta el conjunto de estas situaciones, hemos decidido enfocar nuestro análisis mayoritariamente en nuestras conversaciones para centrarnos en todos los aspectos relevantes. No obstante, las grabaciones de hablantes uruguayos en Alemania siguen formando parte del corpus, ya que nuestras discusiones posteriores se centran a menudo en estas grabaciones de habla y en el presente proyecto.
Para el análisis hemos decidido utilizar entonces los modelos y asimismo los enfoques de Matras y Johanson que hemos trabajado en clase, pues son los que, a nuestro parecer, mejor describen la complejidad de estas interacciones manteniendo un nivel de claridad entendible para un público más general.
Para poder entender mejor por qué elegimos dichos modelos para nuestro análisis, en este blog también mencionaremos brevemente los otros modelos trabajados en el seminario y comentaremos por qué no los tuvimos en cuenta para nuestro análisis.
Autoras: Kira Molina y Marina Cots Terreu