Folgend ist eine Kette von Befehlen aufgelistet, die für spätere Projekte sinnvoll sein können:
In Python Console:
>>> import nltk
>>> nltk.download()
>>> from nltk.corpus import wordnet as wn
>>> print(wn.synset(‚dog.n.01‘).definition())
a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breeds
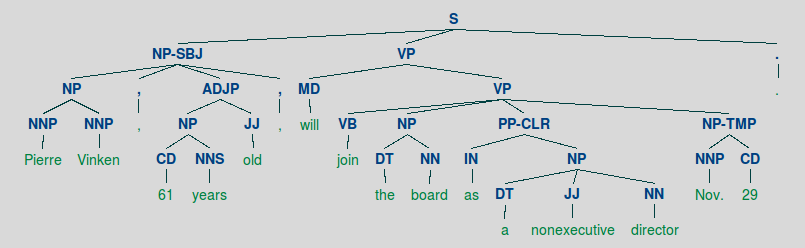
Wordnet NLTK Useage Tokenize and Tag Text
>>> import nltk >>> sentence = """I was feeling very odd this morning.""" >>> tokens = nltk.word_tokenize(sentence) >>> tokens ['I', 'was', 'feeling', 'very', 'odd', 'this', 'morning', '.'] >>> tagged = nltk.pos_tag(tokens) >>> tagged[0:8] [('I', 'PRP'), ('was', 'VBD'), ('feeling', 'VBG'), ('very', 'RB'), ('odd', 'RB'), ('this', 'DT'), ('morning', 'NN'), ('.', '.')] Identify named entities >>> entities = nltk.chunk.ne_chunk(tagged) >>> entities Tree('S', [('I', 'PRP'), ('was', 'VBD'), ('feeling', 'VBG'), ('very', 'RB'), ('odd', 'RB'), ('this', 'DT'), ('morning', 'NN'), ('.', '.')]) Display a parse tree >>> from nltk.corpus import treebank >>> t = treebank.parsed_sents('wsj_0001.mrg')[0] >>> t.draw()>>> from nltk.parse.generate import generate, demo_grammar >>> from nltk import CFG >>> grammar = CFG.fromstring(demo_grammar) >>> print(grammar) Grammar with 13 productions (start state = S) S -> NP VP NP -> Det N PP -> P NP VP -> 'slept' VP -> 'saw' NP VP -> 'walked' PP Det -> 'the' Det -> 'a' N -> 'man' N -> 'park' N -> 'dog' P -> 'in' P -> 'with' >>> for sentence in generate(grammar, depth=10): print(' '.join(sentence)) ... the man slept the man saw the man the man saw the park the man saw the dog the man saw a man the man saw a park the man saw a dog the man walked in the man the man walked in the park [...] a dog walked with a park a dog walked with a dog