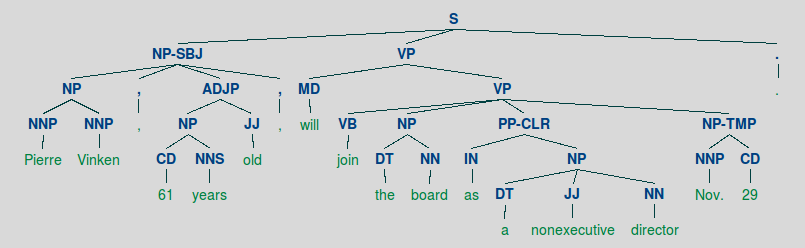
Aufbau der Demo Grammar
November 2nd, 2015Die Demo Grammar ist wie folgt aufgebaut:
from __future__ import print_function
import itertools
import sys
from nltk.grammar import Nonterminal
def generate(grammar, start=None, depth=None, n=None):
„““
Generates an iterator of all sentences from a CFG.
:param grammar: The Grammar used to generate sentences.
:param start: The Nonterminal from which to start generate sentences.
:param depth: The maximal depth of the generated tree.
:param n: The maximum number of sentences to return.
:return: An iterator of lists of terminal tokens.
„““
def _generate_all(grammar, items, depth):
if items:
for frag1 in _generate_one(grammar, items[0], depth):
for frag2 in _generate_all(grammar, items[1:], depth):
yield frag1 + frag2
else:
yield []
def _generate_one(grammar, item, depth):
if depth > 0:
if isinstance(item, Nonterminal):
for prod in grammar.productions(lhs=item):
for frag in _generate_all(grammar, prod.rhs(), depth–1):
yield frag
else:
yield [item]
demo_grammar = „““
S -> NP VP
NP -> Det N
PP -> P NP
VP -> ’slept‘ | ’saw‘ NP | ‚walked‘ PP
Det -> ‚the‘ | ‚a‘
N -> ‚man‘ | ‚park‘ | ‚dog‘
P -> ‚in‘ | ‚with‘
„““
if __name__ == ‚__main__‘:
demo()