von Svenja Goers

Taucht ein in die Welt der Datenwissenschaften an der Universität Bremen. Ein Einblick in das Data Science Center zeigt, wie man aus Daten Wissen schafft. Quelle: Pixabay.
Unsere Welt ertrinkt heutzutage regelrecht in Daten. Diese bringen großes Potential mit sich. Denn in ihnen stecken zahlreiche interessante Informationen und Erkenntnisse. Um diese zu gewinnen, müssen Datensätze jedoch sinnvoll ausgewertet werden. Dies ermöglicht die Disziplin Data Science (Datenwissenschaften). Doch was genau steckt hinter dieser noch relativ jungen Disziplin? Wie schafft sie es in der Datenflut den Kopf über Wasser zu halten und dabei Wettervorhersagen, Marketing, Krankheitsdiagnosen und die Erkennung von Fake-News unter einen Hut zu bringen? Und wie kann das Data Science Center der Universität Bremen Forschenden dabei helfen, riesige Datenmengen auszuwerten und Wissen daraus zu generieren?
Eine Welt voller Daten — auch bekannt als ‚Big Data‘
Der Ausdruck Big Data ist inzwischen fast jedem ein Begriff. Doch was genau steckt eigentlich hinter diesem Buzzword? Und warum ist Big Data heute so wichtig? Egal ob wir durch Social-Media-Feeds scrollen, Suchmaschinen befragen, online shoppen, E-Mails verschicken oder Filme und Serien streamen. Überall im Internet hinterlassen wir täglich zahlreiche digitale Spuren. Folglich lässt sich das Wort Big Data mit dem deutschen Begriff Massendaten übersetzen. Big Data umfasst also die Unmengen an Data, die weltweit anfallen und gespeichert werden.
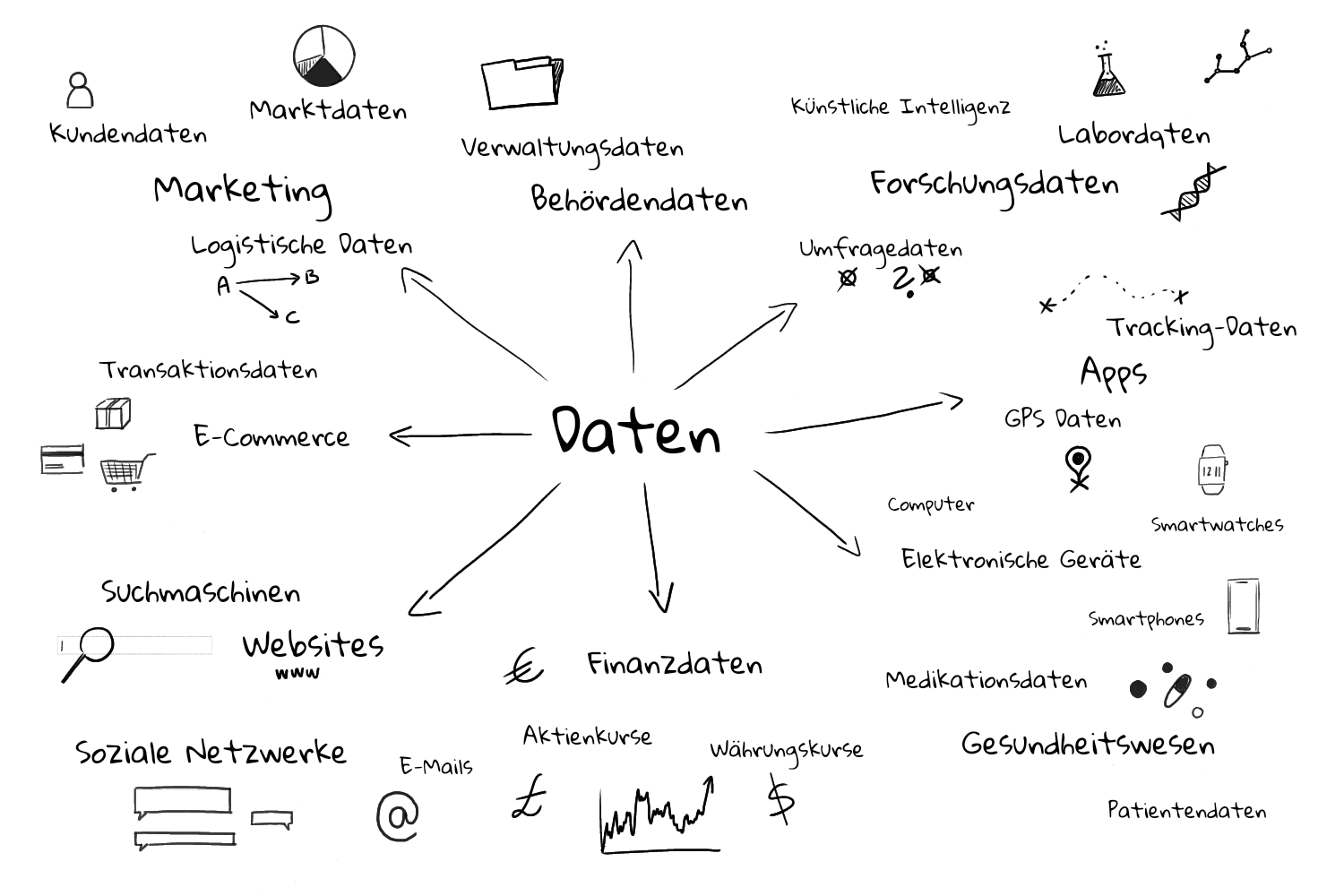
Was genau fällt alles unter den Begriff Big Data? Ein kleiner Überblick über verschiedene Datenformate.
Oft wird das Konzept Big Data durch die sogenannten 3 Vs definiert: Volume, Velocity & Variety [1]. Big Data lässt sich also durch drei Hauptmerkmale charakterisieren: riesige Datenmengen, ein rapides Wachstum des Datenvolumens sowie eine große Datenvielfalt. Letzteres beschreibt die unterschiedlichsten Formen, in denen Daten gespeichert werden können. Dazu gehören zum Beispiel Textdokumente, Bilder, Daten von Internetseiten und Smartphones-Apps, oder Spotify©- , Netflix©- und Social-Media-Algorithmen.
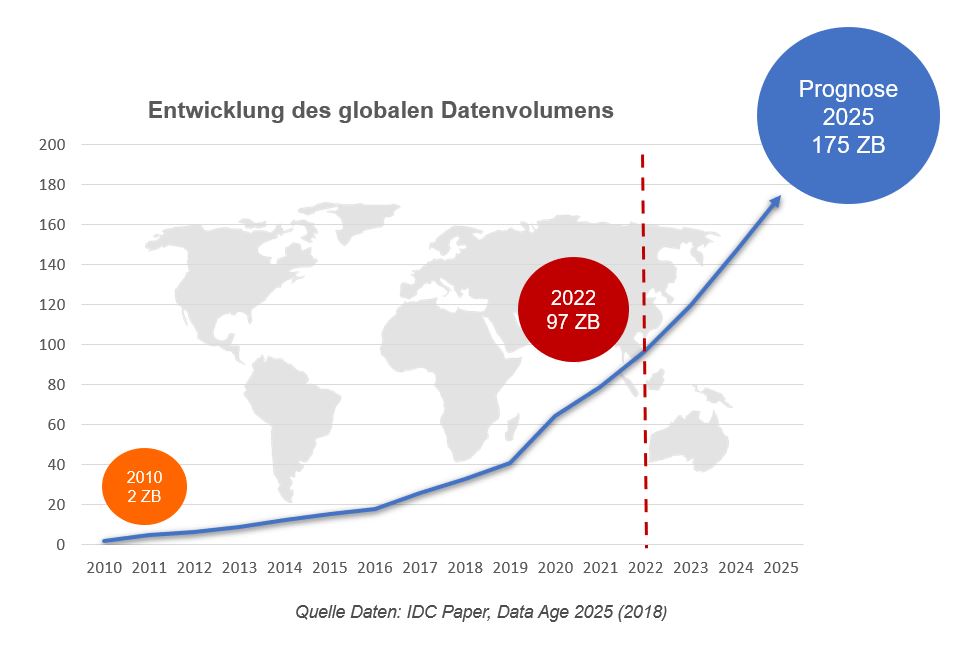
Ein Überblick über die Entwicklung des globalen Datenvolumens.
Dabei ist das weltweit erzeugte Datenvolumen in den letzten Jahren exponentiell angewachsen. Zwischen den Jahren 2012 und 2020 hat sich das globale Datenaufkommen ca. verzehnfacht. Laut Prognosen soll die jährlich produzierte Datenmenge bis zum Jahr 2025 auf bis zu 175 Zettabyte (ZB) anwachsen [2] (siehe Abbildung). Würde man diese 175 ZB auf DVDs speichern, wäre der DVD-Stapel lang genug, um damit die Erde 222 Mal zu umrunden.
Was passiert mit diesen Datenmengen? Das vielfältige Potential von Data Science
Hier kommt der Begriff Data Science (deutsch „Datenwissenschaften“) ins Spiel. Ziel von Data Science ist es, Wissen aus Daten zu generieren. Dafür werden zum Beispiel verschiedene Muster und Trends in Datensätzen herausgearbeitet, um Vorhersagen zu treffen, Zusammenhänge zu erkennen und Aussagen über Risiken und Wahrscheinlichkeiten zu ermöglichen. Somit kann Data Science bspw. verwendet werden, um Wettervorhersagen zu treffen, Serien- und Musikempfehlungen zu geben, schwere Krankheiten zu diagnostizieren oder Fake News von offiziellen Nachrichten zu unterscheiden [3, 4, 5, 6].
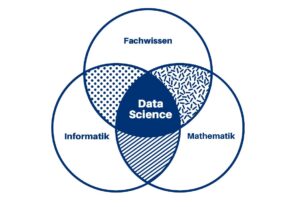
Data Science wird häufig als interdisziplinäre Schlüsseldisziplin bezeichnet.
Data Science lässt sich am besten als Schnittstelle zwischen drei verschiedenen Bereichen beschreiben: Informatik, Mathematik und spezifischem Fachwissen (siehe Abbildung). Letzteres macht die Disziplin besonders vielfältig, da die benötigte Expertise aus den verschiedensten Domänen stammen kann. Folglich sind der Anwendung von Data Science so gut wie keine Grenzen gesetzt. Doch wie genau funktioniert Data Science?
Ein Einblick in das Data Science ABC — Data Mining, Machine- und Deep Learning
Geht es darum, Wissen aus großen Datenmengen zu generieren, spricht man vom sogenannten Data Mining. Wortwörtlich liegt das Ziel des Data Minings darin, wertvolle Informationen aus großen, komplexen Datensätzen „auszugraben“ und „abzubauen“. Dies geschieht, indem bestimmte Trends und Muster in den Daten herausgearbeitet werden. Folglich kommt Data Mining häufig im Kontext von Big Data zum Einsatz. So setzen bspw. viele Unternehmen Data Mining im Marketing ein, um Zielgruppen und Marktsegmente zu definieren.
Neben dem Data Mining stellt außerdem der Bereich des Machine Learning (maschinelles Lernen) einen wichtigen Bestandteil des wachsenden Feldes der Datenwissenschaften dar. Machine Learning ist ein Teilbereich der künstlichen Intelligenz (KI), der auf der Anwendung von großen strukturierten Datensätzen und Algorithmen basiert. Diese ermöglichen künstlichen Systemen wie Menschen zu lernen und sich dabei schrittweise zu verbessern. Eine Unterform des Machine Learning stellt das sogenannte Deep Learning (tiefgehendes Lernen) dar. Dabei können mit Hilfe von künstlichen neuronalen Netzen, die der Struktur des menschlichen Gehirns nachempfunden sind, auch unstrukturierte Datensätze verarbeitet werden.
Der Einsatz von zukunftsrelevanten Technologien wie Machine und Deep Learning wird zurzeit in verschiedensten Bereichen erforscht. So kann Machine Learning bereits jetzt u.a. genutzt werden, um die Parkinson-Krankheit zu diagnostizieren und Brustkrebs in verschiedene Stadien zu erkennen [5, 6]. Im Bereich der Agrarwissenschaften wird aktuell u.a. untersucht, inwiefern Machine Learning eingesetzt werden kann, um Bewässerungssysteme zu managen, das Wohl von Tieren zu überwachen oder Krankheiten in Getreidebeständen zu identifizieren [7]. Die Universität Bremen beteiligt sich bspw. an einem Projekt, dass an der Entwicklung von „künstlich intelligenten“ Zäunen arbeitet. Diese können Wölfe erkennen und vertreiben, um Weidetiere zu schützen [8].
Der Data Science-Werkzeugkasten — wichtige Tools und Techniken
Um zu verstehen wie genau Data Science funktioniert, muss ebenfalls ein kurzer Blick in den Werkzeugkasten der Datenwissenschaften geworfen werden. Dieser ist voll von verschiedenen Tools und Techniken, die es ermöglichen Daten zu sammeln, auszuwerten und zu visualisieren. Mit zu den wichtigsten Werkzeugen gehören Data Science relevante Programmiersprachen wie Python oder R. Diese nutzen Data Scientists, um sich durch riesige Datensätze zu wühlen und diese sinnvoll zu sortieren und zu analysieren. Darüber hinaus ermöglichen diese Programmiersprachen das Arbeiten mit verschiedenen Algorithmen im Bereich des Machine Learnings.
Bei Datenanalysen kommen dabei unterschiedliche Techniken zum Einsatz. Dazu gehören z.B. verschiedene Machine Learning Methoden. Durch Cluster-Analysen können Daten sinnvoll gruppiert werden. Assoziationsanalysen erlauben die Identifizierung von bestimmten Zusammenhängen. Weitere Techniken ermöglichen u.a. das Erkennen von Anomalien oder Ausreißern in einem Datensatz oder das Klassifizieren von Daten wie es in der folgenden Abbildung beispielhaft dargestellt ist.
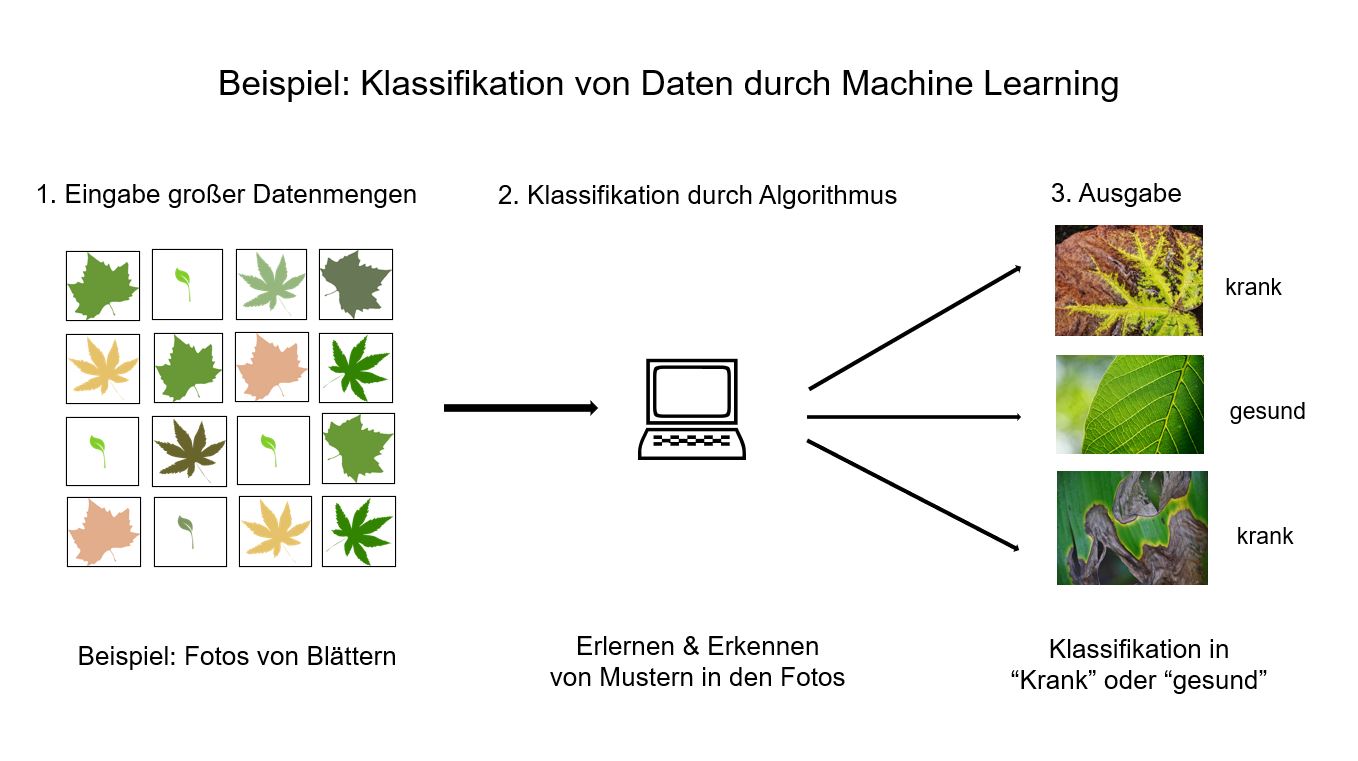
Ein schematisches Beispiel für die Klassifikation von Daten mit Hilfe von Machine Learning.
Das Data Science Center— Datenwissenschaften an der Universität Bremen
![]()
Auch hier an der Universität Bremen werden regelmäßige spannende Forschungs-projekte im Bereich Data Science umgesetzt. Eine wichtige Rolle spielt dabei das Data Science Center (DSC), das im Jahr 2019 als interdisziplinäres Institut für Data Science unter der Leitung von Prof. Dr. Rolf Drechsler an der Universität Bremen gegründet wurde. Das DSC dient als Knotenpunkt und Kontaktstelle für Wissenschaftler*innen aller Fachgebiete, die mit Daten jeglicher Art arbeiten. „Wir im DSC unterstützen Forschende dabei, das Beste aus ihren Daten herauszuholen und so neue Erkenntnisse zu gewinnen,“ erklärt Dr. Lena Steinmann, die Koordinatorin des DSC. Dafür stehen Forschenden am DSC unterschiedliche Angebote zur Verfügung. Dazu gehören bspw. Rechenressourcen für die Umsetzung maschineller Lernverfahren, Datenkompetenz-Trainings und finanzielle Unterstützung und Beratung bei der Umsetzung von Data-Science-Methoden (z.B. Machine Learning).
Darüber hinaus wurde das DSC Team diesen Sommer durch drei Data Stewards ergänzt. Diese bringen Expertise zum Management von Forschungsdaten und Erfahrungen aus verschiedenen Forschungsbereichen mit sich. Zukünftig werden sie Wissenschaftler*innen persönlich beraten, beim Datenmanagement individuell unterstützen und gezielte Trainings anbieten.

Logo und Screenshot der App der Accessible Text App. Foto: Jona Andresen.
Über die finanzielle Unterstützung in Form des DSC Seed Grants wurden seit der Gründung des DSC bereits mehrere spannende Projekte gefördert. Darunter bspw. die Weiterentwicklung einer Smartphone-App, die Nicht-Muttersprachler*innen und Menschen mit kognitiven Einschränkungen das Lesen von Texten erleichtern soll. Mit Hilfe des Einsatzes von Machine Learning-Techniken soll die „Accessible Text App“ Texte für Nutzer*innen vereinfachen und schwierige Begriffe erklären. Dadurch soll Betroffenen mehr Barrierefreiheit im Alltag ermöglicht werden.

Mit Hilfe von Data Science wird erforscht, wie soziale Netzwerke den Kryptowährungsmarkt beeinflussen. Quelle: Pexels.
Im Rahmen eines weiteren DSC Seed Grant Pilotprojekts wird mit unterschiedlichen Data-Science-Verfahren untersucht, inwiefern Diskurse kleinerer Randgruppen auf Social-Media-Plattformen wie Reddit Schwankungen im Kryptowährungsmarkt beeinflussen können. Auch finanzielle Unterstützung für Events im Zusammenhang mit Data Science, wie die Durchführung der internationalen Data-Power-Konferenz im Juni 2022, können über den DSC Seed Grant beantragt werden (wie ihr den DSC Seed Grant beantragen könnt erfahrt ihr hier).
Interesse am Thema Data Science und dem DSC der Uni Bremen geweckt?
Falls ihr selber Forschung im Bereich Data Science betreibt oder betreiben möchtet und Unterstützung bei der Analyse oder dem Management eurer Daten braucht, dann meldet euch gerne direkt bei der DSC Koordinatorin Dr. Lena Steinmann (lena.steinmann@uni-bremen.de).
Weitere Infos zu Events und dem Data Science Center findet ihr außerdem auf der Website (https://www.dsc-ub.de/) oder dem Twitter Account (@DSC_unibremen) des DSC.
Verweise:
[1] De Mauro, A., M. Greco, und M. Grimaldi (2016): “A formal definition of Big Data based on its essential features.” Library Review, 65 (3), S. 122-135.
[2] Reinsel, D, J. Gantz, J. Rydning (2018): Data Age 2025. The Digitization of the World. From Edge to Core. Framingham: International Data Corporation (IDC).
[3] Haupt, S. E., J. Cowie, S. Linden, T. McCandless, B. Kosovic und S. Alessandrini (2018): “Machine learning for applied weather prediction.” 2018 IEEE 14th international conference on e-science (e-Science), S. 276-277.
[4] Ahmad I., M. Yousaf, S. Yousaf und M. O. Ahmad (2020): “Fake news detection using machine learning ensemble methods.” Complexity vol. 2020, o. SS.
[5] Ribli, D., A. Horváth, Z. Unger, P. Pollner und I. Csabai (2018): “Detecting and classifying lesions in mammograms with deep learning.” Scientific reports, 8 (1), S. 1-7.
[6] Mei, J., C. Desrosiers und J. Frasnelli (2021): “Machine learning for the diagnosis of parkinson’s disease: A review of literature.” Frontiers in aging neuroscience, 13, S. 1-41.
[7] Liakos, K. G., Busato, P., Moshou, D., Pearson und S., Bochtis, D. (2018): “Machine learning in agriculture: A review”. Sensors,18 (8), S.1-29.
[8] Bohn, K. U. (2021): „Der intelligente Zaun gegen den Wolf“, URL: https://www.uni-bremen.de/universitaet/hochschulkommunikation-und-marketing/aktuelle-meldungen/detailansicht/der-intelligente-zaun-gegen-den-wolf, Abrufdatum: 30.08.2022.
Links:
Internetseite des DSC: https://www.dsc-ub.de/
Twitter Account des DSC: https://twitter.com/DSC_unibremen
Infos zum DSC Seed Grant: https://www.dsc-ub.de/grant.php



Schreibe einen Kommentar